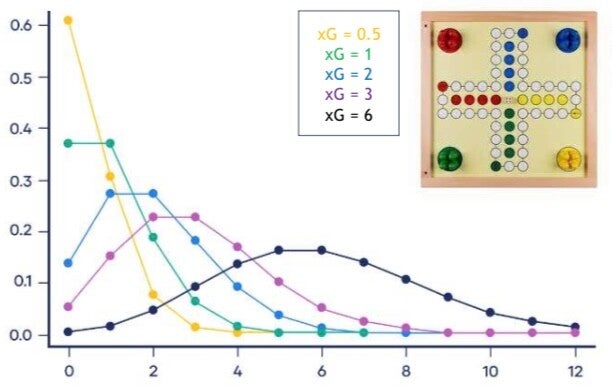
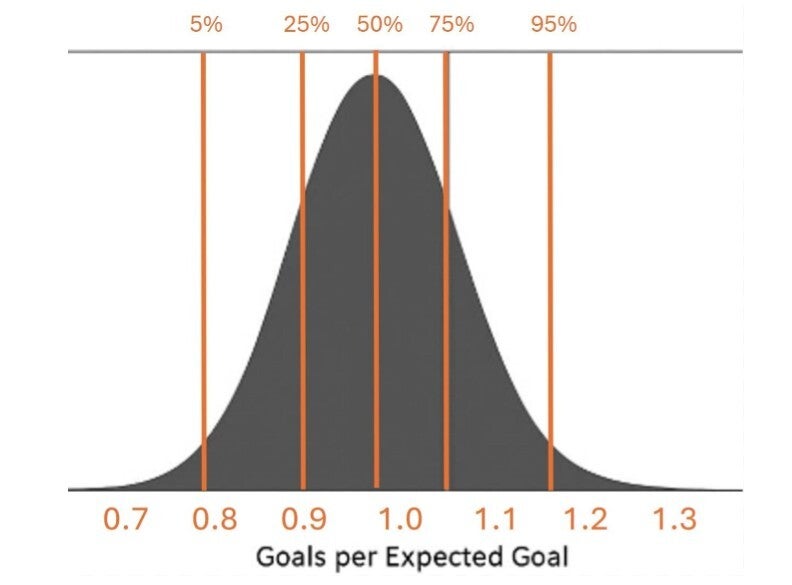
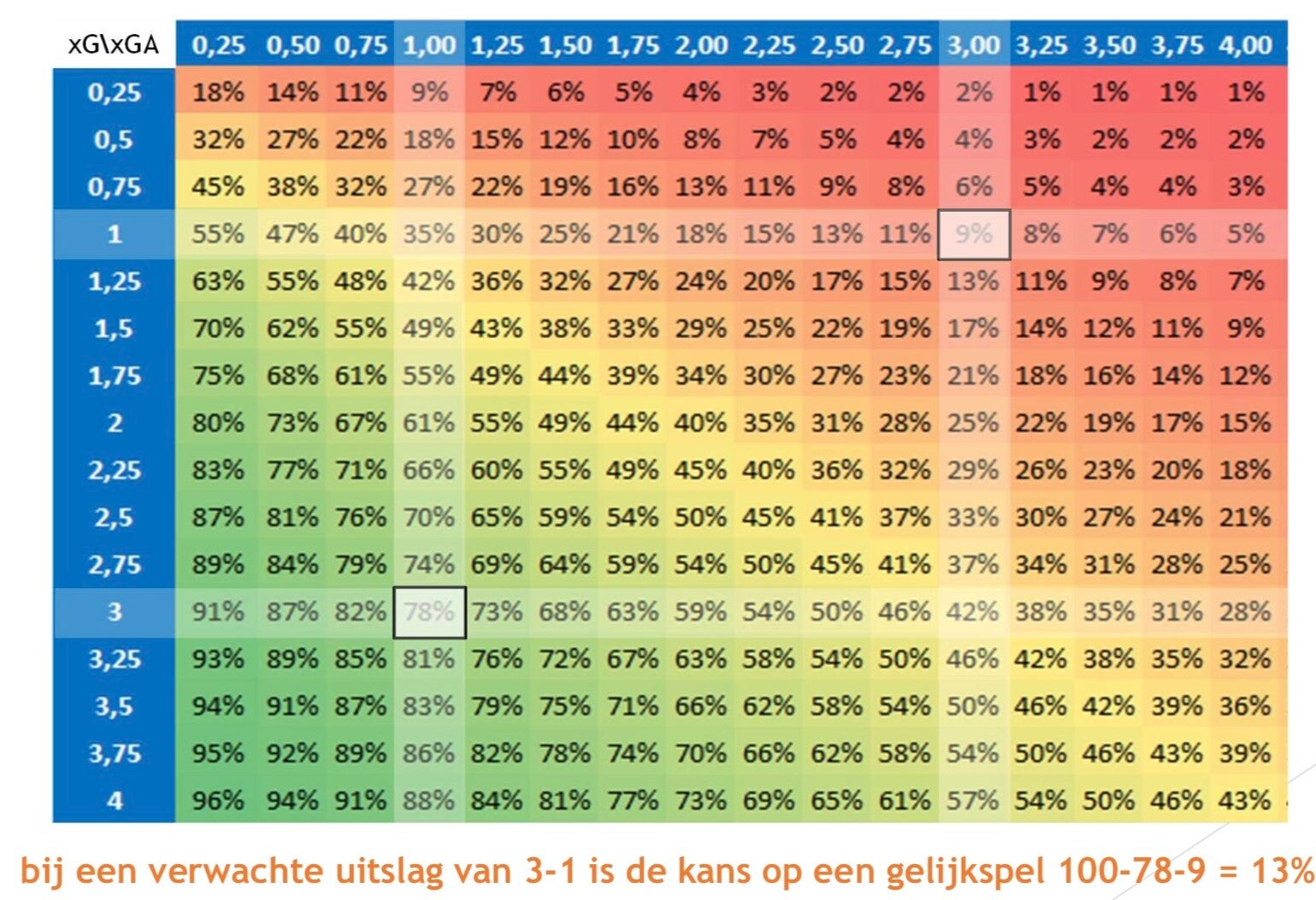
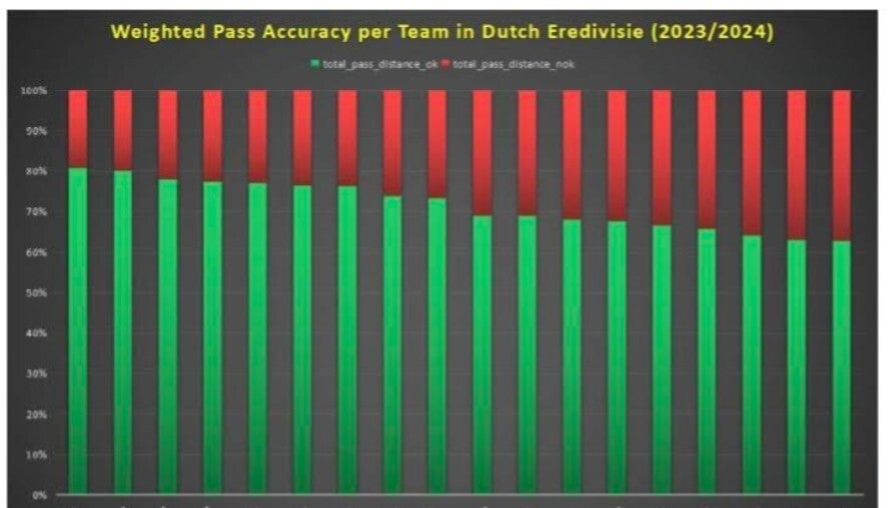
begrip van en grip op data en toeval in (top)sport!
krijg grip op het rendement van je investering door beter te begrijpen hoe data en toeval het verschil maken op het veld
voorkom overhaaste beslissingen na een slechte reeks door inzicht te krijgen in de statistiek achter sportresultaten
breng rust, richting en realisme aan in je organisatie door inzicht te verwerven in de ware betekenis van prestaties
leer wanneer je moet ingrijpen en wanneer je moet volhouden, met heldere inzichten in de rol van data en toeval in prestaties
krijg meer controle en ontwikkel meer zelfvertrouwen door te begrijpen op welke factoren je geen invloed hebt
bekijk je favoriete voetbalclub met een nieuwe blik en ontdek dat achter elke uitslag een wereld van data schuilgaat
koppel je merk aan slimme analyses en vooruitgang door zichtbaar te zijn in een wereld die steeds meer data driven wordt
verrijk je analyses en verhalen met nuance door meer kennis en begrip van de onzichtbare cijfers op het scorebord
til je analyses over het verloop van een wedstrijd of competitie naar een hoger niveau met statistische kennis over toeval
aanleiding en achtergrond
In de sport - en zeker in de voetballerij - is toeval nog altijd een onderschatte factor van betekenis. Een afgeslagen bal, een moment van geluk of pech: het verschil tussen triomfantelijk scoren en hopeloos missen en tussen winnen en verliezen is vaak kleiner dan menigeen denkt. En toch worden er elke dag weer grote beslissingen genomen op basis van uitslagen of prestaties die statistisch gezien maar weinig om het lijf hebben. Dat is een vorm van kapitaalvernietiging die eenvoudigweg niet nodig is.
missie, visie en doelgroep
Als onafhankelijk (sport- en in het bijzonder voetbal)data scientist zie ik het als mijn missie om aan investeerders, aandeelhouders, sponsors, bestuurders, trainers, spelers, fans, journalisten en analisten meer begrip en inzicht te verschaffen in de ware betekenis van data, alsmede de rol en impact van toeval daarin en hoe daarmee om te gaan. Niet om de emoties uit het spel te halen, want die maken het juist zo ongelooflijk mooi en uniek, maar om betere en meer doordachte keuzes te maken, met meer rust, minder paniekzaaierij en een gezondere meer duurzame sport- en organisatiecultuur.
aanpak en werkwijze
Met verhelderende en inzichtelijke analyses, demonstraties, voorbeelden en anekdotes help ik clubs en organisaties om prestaties op zowel collectief als individueel niveau in hun juiste context te plaatsen en niet langer te worden meegesleept of zelfs geleefd door schommelingen die simpelweg bij (top)sport horen. Dat kan zijn in de vorm van een langdurige strategische samenwerking, een tijdelijke consultancy- of adviesopdracht, een bijdrage aan een netwerk- of sponsorbijeenkomst, een kennissessie tijdens een beurs of evenement, een gastcollege aan een onderwijsinstelling, een een- of meerdaagse (in-company) training/cursus of een interactieve lezing of workshop. Alles is mogelijk, denkbaar en bespreekbaar!
meer weten?
Wilt u meer weten over hoe een beter begrip van data, statistiek en kansrekening en meer concreet geluk, pech en toeval kunnen bijdragen aan meer stabiliteit, realiteitszin en vooral rust binnen uw organisatie? Ik denk graag met u mee en neem u graag bij de hand! Vul a.u.b. onderstaand formulier in dan neem ik z.s.m. contact met u op!
op zoek naar praktische voorbeelden en concrete toepassingen? scroll nog even verder...

Gerhard van Dijkhuizen - Independent Football Data Scientist
voorbeelden en praktische toepassingen
klik op de pijltjes voor meer tekst en uitleg!